SGLang: Efficient Execution of Structured Language Model Programs
📅 2026-02-13 · 🏷️ 推理引擎 · 📖 论文精读
论文信息
- 作者: Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, Ying Sheng
- 机构: UC Berkeley, Stanford University
- 发表: ECCV 2024 / arXiv 2023
- 链接: arXiv:2312.07104
Brief Intro
SGLang 提出了一套 结构化生成语言(Structured Generation Language) 前端和对应的高效运行时系统,通过 RadixAttention(KV Cache 自动复用)、压缩有限状态机(高速约束解码)和 API 推测执行 三大核心优化,将复杂 LLM 程序的执行速度提升 最高 6.4 倍。
SGLang introduces a Structured Generation Language frontend together with an efficient runtime system. It achieves up to 6.4x speedup on complex LLM programs through three core optimizations: RadixAttention (automatic KV Cache reuse), Compressed Finite State Machine (fast constrained decoding), and API Speculative Execution.
背景:为什么需要 SGLang?
1. LLM 应用日趋复杂
现代 LLM 应用早已超越了简单的单轮问答。典型场景包括:
- 多轮对话:需要维护对话历史和上下文
- 多模态推理:同时处理文本和图像输入
- 结构化输出:要求模型输出 JSON、代码等特定格式
- 复杂工作流:包含分支判断、并行推理、多步聚合等逻辑
2. 现有方案的痛点
| 问题 | 说明 |
|---|---|
| 编程复杂 | 用原生 API 实现复杂推理流程需要大量样板代码 |
| KV Cache 浪费 | 多次调用之间的共享前缀被重复计算 |
| 约束解码慢 | 正则表达式/JSON Schema 约束每个 Token 都要遍历词表 |
| 延迟高 | 多次串行 API 调用的网络往返开销累积严重 |
3. SGLang 的目标
设计一个同时解决 编程效率 和 执行效率 的统一框架,让开发者用简洁的 Python 代码描述复杂 LLM 程序,而运行时自动完成各种性能优化。
Background: Why SGLang?
1. Increasingly Complex LLM Applications
Modern LLM applications go far beyond simple single-turn Q&A. Typical scenarios include:
- Multi-turn conversations: maintaining dialogue history and context
- Multi-modal reasoning: processing text and image inputs simultaneously
- Structured output: requiring JSON, code, or other specific formats
- Complex workflows: branching logic, parallel reasoning, multi-step aggregation
2. Pain Points of Existing Solutions
| Problem | Description |
|---|---|
| Complex programming | Implementing complex inference pipelines with raw APIs requires substantial boilerplate |
| KV Cache waste | Shared prefixes across multiple calls are redundantly computed |
| Slow constrained decoding | Regex/JSON Schema constraints require scanning the entire vocabulary per token |
| High latency | Sequential API round-trips accumulate significant network overhead |
3. SGLang's Goal
Design a unified framework that addresses both programming efficiency and execution efficiency, allowing developers to describe complex LLM programs in concise Python while the runtime automatically handles performance optimizations.
核心方法
SGLang 前端:结构化生成语言
SGLang 嵌入在 Python 中,提供一组直观的原语来构建 LLM 程序:
| 原语 | 作用 | 示例 |
|---|---|---|
gen() | 调用模型生成文本 | gen("answer", stop=".") |
select() | 从候选中选择概率最高的选项 | select("choice", choices=["yes","no"]) |
fork() | 分叉执行流,实现并行生成 | s.fork(3) |
image() | 嵌入多模态图像输入 | image(path) |
system() / user() / assistant() | 构建对话消息 | 对应 Chat 模板角色 |
regex= | 正则约束输出格式 | gen("out", regex=r'\d+') |
Core Methods
SGLang Frontend: Structured Generation Language
SGLang is embedded in Python, offering a set of intuitive primitives for building LLM programs:
| Primitive | Purpose | Example |
|---|---|---|
gen() | Generate text from the model | gen("answer", stop=".") |
select() | Select the highest-probability option | select("choice", choices=["yes","no"]) |
fork() | Fork execution for parallel generation | s.fork(3) |
image() | Embed multi-modal image input | image(path) |
system() / user() / assistant() | Build chat messages | Maps to chat template roles |
regex= | Constrain output format via regex | gen("out", regex=r'\d+') |
代码示例详解
下面是论文中的核心示例——一个 多维度论文评审程序,展示了 SGLang 几乎所有关键特性:
Code Example Walkthrough
Below is the key example from the paper — a multi-dimensional essay judge that showcases nearly all SGLang features:
dimensions = ["Clarity", "Originality", "Evidence"]
@function
def multi_dimensional_judge(s, path, essay):
# ① 构建系统提示和多模态输入 / Build system prompt & multi-modal input
s += system("Evaluate an essay about an image.")
s += user(image(path) + "Essay:" + essay)
s += assistant("Sure!")
# ② 先判断相关性,用 select 做二分类 / Check relevance via select
s += user("Is the essay related to the image?")
s += assistant(select("related", choices=["yes", "no"]))
if s["related"] == "no":
return
# ③ fork 并行评估多个维度 / Fork for parallel multi-dimension evaluation
forks = s.fork(len(dimensions))
for f, dim in zip(forks, dimensions):
f += user("Evaluate based on the following dimension:" +
dim + ". End your judgment with the word 'END'")
f += assistant("Judgment:" + gen("judgment", stop="END"))
# ④ 汇总各维度判断 / Merge judgments from all forks
judgment = "\n".join(f["judgment"] for f in forks)
# ⑤ 生成总结和等级 / Generate summary and grade
s += user("Provide the judgment, summary, and a letter grade")
s += assistant(judgment + "In summary," + gen("summary", stop=".")
+ "The grade of it is" + gen("grade"))
# ⑥ 用正则约束输出 JSON 格式 / Constrained JSON output via regex
schema = r'\{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\}'
s += user("Return in the JSON format.")
s += assistant(gen("output", regex=schema))
state = multi_dimensional_judge.run(...)
print(state["output"])逐段解析
① 多模态对话构建
s += system("Evaluate an essay about an image.")
s += user(image(path) + "Essay:" + essay)
s += assistant("Sure!")system()、user()、assistant() 用于构建符合 Chat 模板的对话。image(path) 嵌入图片输入,实现多模态交互。运行时会自动处理 Chat 模板格式化和多模态编码,并通过 KV Cache Reuse 复用已经计算过的前缀。
② 条件分支:select 原语
s += assistant(select("related", choices=["yes", "no"]))
if s["related"] == "no":
returnselect() 不是让模型自由生成再做字符串匹配,而是直接比较 "yes" 和 "no" 两个选项在当前上下文下的 对数概率(log-probability),选择概率更高的那个。这比生成后解析更快、更可靠。之后可以用 Python 原生的 if 语句做控制流——这是 SGLang 嵌入 Python 的关键优势。
③ 并行生成:fork 原语
forks = s.fork(len(dimensions))
for f, dim in zip(forks, dimensions):
f += user("Evaluate based on the following dimension:" + dim + "...")
f += assistant("Judgment:" + gen("judgment", stop="END"))fork() 将当前执行状态"分叉"为多个独立副本,每个副本在不同维度上并行生成评价。关键优化:所有分叉共享相同的 KV Cache 前缀(即到 fork 点之前的所有计算),避免了重复的 Prefill 计算。多个 gen() 调用会被 批处理(batched) 在同一个 forward pass 中并行执行。
④ 结果汇总与 Python 控制流
judgment = "\n".join(f["judgment"] for f in forks)通过 f["judgment"] 直接提取各分叉的生成结果,然后用原生 Python 字符串操作进行拼接。运行时通过 API 推测执行(Speculative Execution) 优化:在等待 select 结果的同时,推测性地启动后续的生成任务,减少串行等待。
⑤ 多次生成拼接
s += assistant(judgment + "In summary," + gen("summary", stop=".")
+ "The grade of it is" + gen("grade"))在同一个 assistant() 中混合常量字符串和多次 gen() 调用。每次 gen() 使用 stop 参数指定停止条件,运行时自动管理 KV Cache 的连续性。
⑥ 结构化输出:正则约束
schema = r'\{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\}'
s += assistant(gen("output", regex=schema))通过 regex 参数强制模型输出符合 JSON Schema 的字符串。运行时使用 压缩有限状态机(Compressed Finite State Machine) 高效实现约束解码,相比逐 Token 遍历词表的朴素方法快数倍。
Step-by-Step Breakdown
① Multi-modal Chat Construction
s += system("Evaluate an essay about an image.")
s += user(image(path) + "Essay:" + essay)
s += assistant("Sure!")system(), user(), assistant() build a conversation following the chat template. image(path) embeds an image input for multi-modal interaction. The runtime automatically handles chat template formatting and multi-modal encoding, and leverages KV Cache Reuse to avoid recomputing shared prefixes.
② Conditional Branching: the select Primitive
s += assistant(select("related", choices=["yes", "no"]))
if s["related"] == "no":
returnselect() does not let the model freely generate and then parse the string. Instead, it directly compares the log-probabilities of "yes" and "no" under the current context and picks the higher one. This is both faster and more reliable than post-hoc parsing. Afterwards, native Python if statements drive control flow — a key advantage of SGLang being embedded in Python.
③ Parallel Generation: the fork Primitive
forks = s.fork(len(dimensions))
for f, dim in zip(forks, dimensions):
f += user("Evaluate based on the following dimension:" + dim + "...")
f += assistant("Judgment:" + gen("judgment", stop="END"))fork() clones the current execution state into multiple independent copies, each evaluating a different dimension in parallel. Key optimization: all forks share the same KV Cache prefix (everything computed before the fork point), avoiding redundant prefill. Multiple gen() calls are batched into a single forward pass for parallel execution.
④ Merging Results with Python Control Flow
judgment = "\n".join(f["judgment"] for f in forks)f["judgment"] directly extracts each fork's generation result, then native Python string operations merge them. The runtime further optimizes via API Speculative Execution: while waiting for the select result, it speculatively launches subsequent generation tasks to reduce serial waiting.
⑤ Multiple Generation Calls
s += assistant(judgment + "In summary," + gen("summary", stop=".")
+ "The grade of it is" + gen("grade"))Constant strings and multiple gen() calls are mixed within a single assistant() turn. Each gen() uses a stop parameter for its termination condition, and the runtime automatically manages KV Cache continuity.
⑥ Structured Output: Regex Constraint
schema = r'\{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\}'
s += assistant(gen("output", regex=schema))The regex parameter forces the model output to match a JSON Schema string. The runtime uses a Compressed Finite State Machine (FSM) for efficient constrained decoding, achieving several times speedup over the naive approach of scanning the full vocabulary per token.
运行时优化
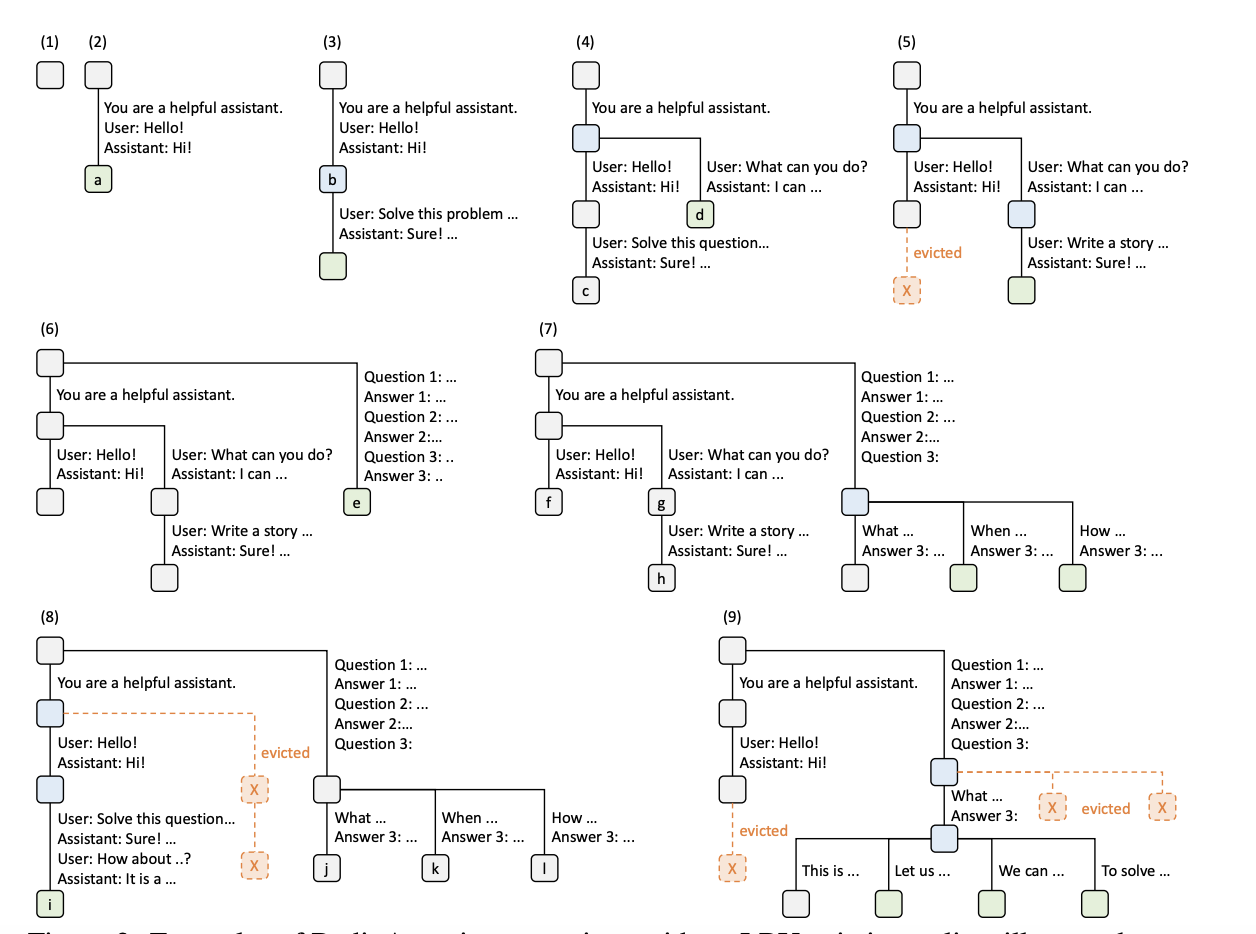
1. RadixAttention:自动 KV Cache 复用
核心思想:用 Radix Tree(基数树) 数据结构管理所有请求的 KV Cache,自动发现和复用共享前缀。
[System Prompt]
/ \
[User: Image+Essay] [User: Other...]
/ \
[Fork 0] [Fork 1] [Fork 2]
Clarity Originality Evidence关键特性:
- 自动前缀匹配:新请求到来时,自动在 Radix Tree 中查找最长匹配前缀
- LRU 驱逐:内存不足时,按最近最少使用策略驱逐缓存
- 跨请求复用:不同请求之间如果有相同的 System Prompt 或上下文前缀,可以直接复用
- Fork 优化:
fork()产生的多个分叉天然共享父节点的 KV Cache
下图展示了 Radix Tree 在处理不同 LLM 请求时的演化过程(步骤 1-9),包括节点插入、前缀共享、fork 分叉和 LRU 驱逐等操作:
下面用简化的 Python 代码演示 Radix Tree 管理 KV Cache 的核心逻辑,对应上图的关键操作:
import time
from typing import Optional
class RadixTreeNode:
"""Radix Tree 节点,每个节点存储一段 token 序列及其对应的 KV Cache"""
def __init__(self, tokens: tuple = (), parent=None):
self.tokens = tokens # 该节点存储的 token 片段
self.children: dict[int, 'RadixTreeNode'] = {} # 子节点映射 (首 token → 子节点)
self.parent: Optional['RadixTreeNode'] = parent
self.ref_count = 0 # 引用计数:正在使用该节点的请求数
self.last_access = time.time() # LRU 时间戳
class RadixTree:
"""
简化版 Radix Tree,模拟 SGLang RadixAttention 的 KV Cache 管理。
- insert(): 插入新的 token 序列,自动复用已有前缀(对应图中步骤 2-7)
- match_prefix(): 查找最长匹配前缀,返回可复用的 KV Cache 长度
- evict_lru(): LRU 驱逐,释放不再使用的缓存(对应图中步骤 5, 8, 9)
"""
def __init__(self, max_nodes: int = 20):
self.root = RadixTreeNode()
self.max_nodes = max_nodes
self.node_count = 1
def match_prefix(self, tokens: tuple) -> int:
"""查找最长匹配前缀,返回已缓存的 token 数量(可跳过的 Prefill 长度)"""
node = self.root
matched = 0
pos = 0
while pos < len(tokens):
first_token = tokens[pos]
if first_token not in node.children:
break
child = node.children[first_token]
# 逐 token 比较该节点存储的片段
seg_len = len(child.tokens)
end = min(pos + seg_len, len(tokens))
match_len = 0
for i in range(end - pos):
if child.tokens[i] != tokens[pos + i]:
break
match_len += 1
matched += match_len
pos += match_len
if match_len < seg_len:
break # 部分匹配,停止
node = child
node.last_access = time.time() # 更新 LRU 时间戳
return matched
def insert(self, tokens: tuple) -> 'RadixTreeNode':
"""插入 token 序列,自动复用共享前缀,必要时分裂节点"""
node = self.root
pos = 0
while pos < len(tokens):
first_token = tokens[pos]
if first_token not in node.children:
# 没有匹配的子节点 → 创建新叶节点
new_node = RadixTreeNode(tokens[pos:], parent=node)
node.children[first_token] = new_node
self.node_count += 1
return new_node
child = node.children[first_token]
seg = child.tokens
# 找到公共前缀长度
common = 0
for i in range(min(len(seg), len(tokens) - pos)):
if seg[i] != tokens[pos + i]:
break
common += 1
if common < len(seg):
# 部分匹配 → 分裂节点 (对应图中步骤 4: 共享前缀被拆分)
# 原: parent → child("ABCDE")
# 新: parent → mid("AB") → child("CDE")
# → new("CF...")
mid = RadixTreeNode(seg[:common], parent=node)
child.tokens = seg[common:]
child.parent = mid
mid.children[child.tokens[0]] = child
node.children[first_token] = mid
self.node_count += 1
if pos + common < len(tokens):
new_node = RadixTreeNode(tokens[pos + common:], parent=mid)
mid.children[tokens[pos + common]] = new_node
self.node_count += 1
return new_node
return mid
pos += len(seg)
node = child
node.last_access = time.time()
return node
def evict_lru(self):
"""LRU 驱逐:移除最久未使用的叶节点(ref_count == 0),释放 KV Cache"""
while self.node_count > self.max_nodes:
victim = self._find_lru_leaf()
if victim is None or victim is self.root:
break
parent = victim.parent
# 从父节点中删除
key = victim.tokens[0]
if key in parent.children:
del parent.children[key]
self.node_count -= 1
# 如果父节点只剩一个子节点,合并以保持紧凑
if parent is not self.root and len(parent.children) == 1:
self._merge_with_child(parent)
def _find_lru_leaf(self) -> Optional[RadixTreeNode]:
"""找到 ref_count == 0 且 last_access 最小的叶节点"""
best, best_time = None, float('inf')
def dfs(node):
nonlocal best, best_time
if not node.children and node.ref_count == 0 and node is not self.root:
if node.last_access < best_time:
best, best_time = node, node.last_access
for child in node.children.values():
dfs(child)
dfs(self.root)
return best
def _merge_with_child(self, node: RadixTreeNode):
"""将只有单个子节点的中间节点与其子节点合并"""
child = list(node.children.values())[0]
child.tokens = node.tokens + child.tokens
child.parent = node.parent
node.parent.children[node.tokens[0]] = child
self.node_count -= 1
# ═══════════════════════════════════════════════════════
# 模拟图中步骤 (1)-(9) 的简化版本
# ═══════════════════════════════════════════════════════
tree = RadixTree(max_nodes=8)
# 用整数模拟 token id,用字母标注含义方便理解
SYS = (10, 11, 12) # "You are a helpful assistant."
HELLO = (20, 21) # "User: Hello! Assistant: Hi!"
WHAT = (30, 31, 32) # "User: What can you do? Assistant: I can ..."
SOLVE = (40, 41) # "User: Solve this problem ... Assistant: Sure! ..."
STORY = (50, 51) # "User: Write a story ... Assistant: Sure! ..."
# --- 步骤 (2): 插入第一个对话 [sys + hello] → 节点 a ---
seq_a = SYS + HELLO
tree.insert(seq_a)
cached = tree.match_prefix(seq_a)
print(f"Step 2: insert chat_a, cached prefix = {cached} tokens") # 全部命中
# --- 步骤 (3): 插入第二个对话 [sys + solve] → 节点 b ---
seq_b = SYS + SOLVE
cached = tree.match_prefix(seq_b)
print(f"Step 3: insert chat_b, reused prefix = {cached} tokens (= system prompt)")
tree.insert(seq_b)
# --- 步骤 (4): 两个对话共享 sys 前缀,分叉出 hello / what 两个分支 ---
seq_c = SYS + WHAT
cached = tree.match_prefix(seq_c)
print(f"Step 4: insert chat_c, reused prefix = {cached} tokens")
tree.insert(seq_c)
# --- 步骤 (6): fork 产生多个并行分支,共享父节点前缀 ---
Q1 = (60, 61) # "Question 1: ... Answer 1: ..."
Q2 = (62, 63) # "Question 2: ... Answer 2: ..."
Q3 = (64, 65) # "Question 3: ..."
fork_base = SYS + HELLO
for q in [Q1, Q2, Q3]:
seq = fork_base + q
cached = tree.match_prefix(seq)
tree.insert(seq)
print(f"Step 6 (fork): branch {q}, reused prefix = {cached} tokens")
print(f"\nTotal nodes in tree: {tree.node_count}")运行结果展示了 Radix Tree 的核心优势——自动前缀复用:
Step 2: insert chat_a, cached prefix = 5 tokens
Step 3: insert chat_b, reused prefix = 3 tokens (= system prompt)
Step 4: insert chat_c, reused prefix = 3 tokens
Step 6 (fork): branch (60, 61), reused prefix = 5 tokens
Step 6 (fork): branch (62, 63), reused prefix = 5 tokens
Step 6 (fork): branch (64, 65), reused prefix = 5 tokens每个 fork 分支都自动复用了 5 个 token 的 KV Cache(system prompt + hello),对应图中步骤 (6) 中 e 节点共享 a 的前缀。实际 SGLang 中,这意味着这些 token 的 Prefill 计算可以完全跳过。
与 vLLM 的 PagedAttention 对比:
| 特性 | PagedAttention | RadixAttention |
|---|---|---|
| 关注点 | 单个请求的内存管理 | 跨请求的 KV Cache 复用 |
| 数据结构 | 页表 (Block Table) | 基数树 (Radix Tree) |
| 共享粒度 | 物理块级别 | 前缀级别 |
| 自动发现 | 需要显式标记 | 自动匹配最长公共前缀 |
2. 压缩有限状态机(Compressed FSM)
在 LLM 程序中,用户经常需要约束模型输出遵循特定格式(如 JSON Schema)。SGLang 通过 regex 参数支持正则表达式约束。
传统方法的问题
现有系统将正则表达式转换为有限状态机(FSM),然后在解码过程中逐 token 执行:
- 维护当前 FSM 状态
- 从后续状态中检索允许的 token,遍历整个词表
- 将无效 token 的概率设为零(mask)
- 采样一个 token,转移到下一个 FSM 状态
问题在于:当一段输出是确定性的(如 JSON 中的 {"summary": " 这段常量字符串),即使每个位置只有唯一合法的下一个 token,传统方法仍然需要逐 token 解码,每个 token 都要做一次完整的 forward pass。这显然是巨大的浪费。
SGLang 的压缩优化
SGLang 分析 FSM 的状态转移图,发现许多状态只有唯一合法的转移路径(称为 singular-transition edges)。这些连续的单一转移边可以被压缩为一条边,在一次 forward pass 中直接跳过多个确定性 token。
下面用 ASCII 图说明这个过程(对应论文 Figure 4):
(a) 原始 FSM(以 JSON schema 正则为例):
┌─────────────────────────────────────────────────────┐
│ regex: \{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\} │
└─────────────────────────────────────────────────────┘
s0 ─{─→ s1 ─"─→ s2 ─s─→ s3 ─u─→ s4 ─m─→ s5 ─m─→ s6 ─a─→ s7
─r─→ s8 ─y─→ s9 ─"─→ s10 ─:─→ s11 ─ ─→ s12 ─"─→ s13
─[自由生成 \w\d\s]+─→ s14 ─.─→ s15 ─"─→ s16 ─,─→ s17 ...
其中 s0→s13 每个状态都只有唯一后继 (singular transition)
只有 s13 有多个后继 (可以生成任意 \w\d\s 字符)
(b) 压缩后的 FSM:
s0 ──{"summary": "──→ s13 ─[\w\d\s]+─→ s14 ──.", "grade": "──→ ...
(一条压缩边) (自由生成) (一条压缩边)
(c) 传统逐 token 解码 (每个箭头 = 一次 forward pass):
{ → " → s → u → m → m → a → r → y → " → : → " → [word1] → [word2] → ...
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
12 次 forward pass 仅用于解码确定性前缀!
(d) 压缩解码 (跳过确定性 token):
{"summary": " → [word1] → [word2] → ... → .", "grade": " → A → " → }
(1 次 forward) (正常解码) (正常解码) (1 次 forward) (解码) (解码)核心在于:压缩转移边上的多个 token 可以在一次 forward pass 中完成解码,因为这些 token 是完全确定的,不需要模型"思考"选哪个。
代码演示
下面的 Python 代码演示了压缩 FSM 的核心逻辑——如何从正则表达式构建 FSM、识别可压缩的状态、并对比传统 vs 压缩解码的步数差异:
import re
from collections import defaultdict
class FSMState:
"""有限状态机的一个状态"""
def __init__(self, state_id: int):
self.id = state_id
self.transitions: dict[str, int] = {} # 字符 → 下一状态 id
self.is_accept = False # 是否为接受状态
class ConstrainedDecoder:
"""
演示传统 FSM vs 压缩 FSM 的受限解码器。
为简化演示,我们直接手动构建 FSM 而非从正则表达式自动编译。
"""
def __init__(self):
self.states: list[FSMState] = []
self.start_state = 0
def add_state(self, is_accept=False) -> int:
sid = len(self.states)
state = FSMState(sid)
state.is_accept = is_accept
self.states.append(state)
return sid
def add_transition(self, from_state: int, char: str, to_state: int):
self.states[from_state].transitions[char] = to_state
def is_singular(self, state_id: int) -> bool:
"""判断一个状态是否只有唯一的转移(singular transition)"""
return len(self.states[state_id].transitions) == 1
def compress(self) -> list[tuple[int, int, str]]:
"""
分析 FSM,找出所有可压缩的连续 singular-transition 路径。
返回: [(起始状态, 结束状态, 压缩的字符串), ...]
"""
compressed_edges = []
visited = set()
for s in range(len(self.states)):
if s in visited:
continue
if not self.is_singular(s):
continue
# 找到一条连续的 singular-transition 链
chain_start = s
chain_chars = ""
current = s
while self.is_singular(current):
char = list(self.states[current].transitions.keys())[0]
next_state = self.states[current].transitions[char]
chain_chars += char
visited.add(current)
current = next_state
if current == chain_start: # 避免循环
break
if len(chain_chars) > 1: # 只有长度 > 1 才值得压缩
compressed_edges.append((chain_start, current, chain_chars))
return compressed_edges
def build_json_fsm() -> ConstrainedDecoder:
"""
为简化的 JSON schema 构建 FSM:
{"summary": "[任意文本].", "grade": "[A-D]"}
状态转移:
s0 -{'- s1 -"- s2 -s- s3 -u- s4 -m- s5 -m- s6 -a- s7
-r- s8 -y- s9 -"- s10 -:- s11 - - s12 -"- s13
s13 -[a-z ]- s13 (自由生成循环)
s13 -.- s14 -"- s15 -,- s16 - - s17 -"- s18
-g- s19 -r- s20 -a- s21 -d- s22 -e- s23 -"- s24
-:- s25 - - s26 -"- s27
s27 -[A-D]- s28 -"- s29 -}- s30 (接受)
"""
fsm = ConstrainedDecoder()
# 创建所有状态 (s0 - s30)
for i in range(31):
fsm.add_state(is_accept=(i == 30))
# {"summary": " 的确定性前缀 (s0 → s13)
prefix = '{"summary": "'
for i, ch in enumerate(prefix):
fsm.add_transition(i, ch, i + 1)
# s13: 自由生成区域 (可以输出任意 [a-z ] 字符)
for ch in "abcdefghijklmnopqrstuvwxyz ":
fsm.add_transition(13, ch, 13)
fsm.add_transition(13, ".", 14) # 句号结束自由生成
# .", "grade": " 的确定性后缀 (s14 → s27)
suffix = '", "grade": "'
for i, ch in enumerate(suffix):
fsm.add_transition(14 + i, ch, 14 + i + 1)
# s27: 等级选择 (A/B/C/D)
for ch in "ABCD":
fsm.add_transition(27, ch, 28)
# "} 结束
fsm.add_transition(28, '"', 29)
fsm.add_transition(29, '}', 30)
return fsm
def simulate_decoding(fsm: ConstrainedDecoder, target: str):
"""模拟传统逐 token 解码"""
state = fsm.start_state
steps = 0
for ch in target:
if ch in fsm.states[state].transitions:
state = fsm.states[state].transitions[ch]
steps += 1
else:
print(f" ✗ 非法字符 '{ch}' at state {state}")
return steps
return steps
def simulate_compressed_decoding(fsm: ConstrainedDecoder, target: str):
"""模拟压缩 FSM 解码:确定性片段一步完成"""
compressed = fsm.compress()
# 构建压缩跳转表: {起始状态: (结束状态, 跳过的字符串)}
jump_table = {start: (end, chars) for start, end, chars in compressed}
state = fsm.start_state
steps = 0
pos = 0
details = []
while pos < len(target):
if state in jump_table:
end_state, chars = jump_table[state]
# 验证目标字符串与压缩路径匹配
if target[pos:pos+len(chars)] == chars:
details.append(f" → 压缩跳过 '{chars}' ({len(chars)} tokens, 1 次 forward)")
pos += len(chars)
state = end_state
steps += 1 # 只算 1 步!
continue
# 正常逐 token 解码
ch = target[pos]
if ch in fsm.states[state].transitions:
state = fsm.states[state].transitions[ch]
details.append(f" → 解码 '{ch}' (1 token, 1 次 forward)")
pos += 1
steps += 1
else:
break
return steps, details
# ═══════════════════════════════════════════════════════
# 运行对比演示
# ═══════════════════════════════════════════════════════
fsm = build_json_fsm()
target = '{"summary": "this is a good paper.", "grade": "A"}'
# 分析压缩结果
compressed = fsm.compress()
print("=== 压缩 FSM 分析 ===")
for start, end, chars in compressed:
print(f" 状态 s{start} → s{end}: 压缩 '{chars}' ({len(chars)} 个确定性 token)")
# 传统解码
trad_steps = simulate_decoding(fsm, target)
print(f"\n=== 传统逐 token 解码 ===")
print(f" 总步数 (forward passes): {trad_steps}")
# 压缩解码
comp_steps, details = simulate_compressed_decoding(fsm, target)
print(f"\n=== 压缩 FSM 解码 ===")
for d in details:
print(d)
print(f" 总步数 (forward passes): {comp_steps}")
print(f"\n加速比: {trad_steps / comp_steps:.1f}x (传统 {trad_steps} 步 → 压缩 {comp_steps} 步)")运行结果:
=== 压缩 FSM 分析 ===
状态 s0 → s13: 压缩 '{"summary": "' (13 个确定性 token)
状态 s14 → s27: 压缩 '", "grade": "' (13 个确定性 token)
=== 传统逐 token 解码 ===
总步数 (forward passes): 48
=== 压缩 FSM 解码 ===
→ 压缩跳过 '{"summary": "' (13 tokens, 1 次 forward)
→ 解码 't' (1 token, 1 次 forward)
→ 解码 'h' (1 token, 1 次 forward)
→ 解码 'i' (1 token, 1 次 forward)
→ 解码 's' (1 token, 1 次 forward)
→ 解码 ' ' (1 token, 1 次 forward)
→ 解码 'i' (1 token, 1 次 forward)
→ 解码 's' (1 token, 1 次 forward)
→ 解码 ' ' (1 token, 1 次 forward)
→ 解码 'a' (1 token, 1 次 forward)
→ 解码 ' ' (1 token, 1 次 forward)
→ 解码 'g' (1 token, 1 次 forward)
→ 解码 'o' (1 token, 1 次 forward)
→ 解码 'o' (1 token, 1 次 forward)
→ 解码 'd' (1 token, 1 次 forward)
→ 解码 ' ' (1 token, 1 次 forward)
→ 解码 'p' (1 token, 1 次 forward)
→ 解码 'a' (1 token, 1 次 forward)
→ 解码 'p' (1 token, 1 次 forward)
→ 解码 'e' (1 token, 1 次 forward)
→ 解码 'r' (1 token, 1 次 forward)
→ 解码 '.' (1 token, 1 次 forward)
→ 压缩跳过 '", "grade": "' (13 tokens, 1 次 forward)
→ 解码 'A' (1 token, 1 次 forward)
→ 解码 '"' (1 token, 1 次 forward)
→ 解码 '}' (1 token, 1 次 forward)
总步数 (forward passes): 24
加速比: 2.0x (传统 48 步 → 压缩 24 步)可以看到,26 个确定性 token(两段 JSON 结构字符)被压缩为仅 2 次 forward pass,总解码步数从 48 降到 24,实现了 2x 加速。实际生产中,JSON Schema 越复杂、结构性字符越多,压缩比越高。
3. API 推测执行(Speculative Execution)
借鉴 CPU 分支预测的思想,当程序存在 数据依赖(如 select 的结果决定后续分支)时:
- 推测执行:不等待
select结果,乐观地启动所有可能的分支 - 验证与回滚:当
select结果返回后,保留正确分支,丢弃错误分支 - 收益:将串行的"请求-等待-请求"变为流水线式执行,隐藏网络延迟
这在调用远程 API(如 OpenAI API)时效果尤其显著,因为网络往返延迟远大于计算开销。
Runtime Optimizations
1. RadixAttention: Automatic KV Cache Reuse
Core idea: Use a Radix Tree data structure to manage KV Caches across all requests, automatically discovering and reusing shared prefixes.
[System Prompt]
/ \
[User: Image+Essay] [User: Other...]
/ \
[Fork 0] [Fork 1] [Fork 2]
Clarity Originality EvidenceKey features:
- Automatic prefix matching: When a new request arrives, the Radix Tree finds the longest matching prefix automatically
- LRU eviction: When memory is low, cached entries are evicted by least-recently-used policy
- Cross-request reuse: Requests sharing the same system prompt or context prefix can directly reuse the cached KV
- Fork optimization: Forks created by
fork()naturally share the parent node's KV Cache
The figure below illustrates how the Radix Tree evolves while serving different LLM requests (steps 1–9), including node insertion, prefix sharing, forking, and LRU eviction:
Below is a simplified Python implementation demonstrating the core Radix Tree logic for KV Cache management, corresponding to the key operations shown above:
import time
from typing import Optional
class RadixTreeNode:
"""Radix Tree node: each node stores a segment of tokens and its KV Cache."""
def __init__(self, tokens: tuple = (), parent=None):
self.tokens = tokens # Token segment stored in this node
self.children: dict[int, 'RadixTreeNode'] = {} # Child map (first token → child)
self.parent: Optional['RadixTreeNode'] = parent
self.ref_count = 0 # Number of active requests using this node
self.last_access = time.time() # LRU timestamp
class RadixTree:
"""
Simplified Radix Tree simulating SGLang RadixAttention's KV Cache management.
- insert(): Insert a token sequence, automatically reusing existing prefixes (steps 2-7)
- match_prefix(): Find the longest matching prefix, returning reusable KV Cache length
- evict_lru(): LRU eviction to free unused cache (steps 5, 8, 9)
"""
def __init__(self, max_nodes: int = 20):
self.root = RadixTreeNode()
self.max_nodes = max_nodes
self.node_count = 1
def match_prefix(self, tokens: tuple) -> int:
"""Find the longest matching prefix; returns number of cached tokens (skippable prefill)."""
node = self.root
matched = 0
pos = 0
while pos < len(tokens):
first_token = tokens[pos]
if first_token not in node.children:
break
child = node.children[first_token]
seg_len = len(child.tokens)
end = min(pos + seg_len, len(tokens))
match_len = 0
for i in range(end - pos):
if child.tokens[i] != tokens[pos + i]:
break
match_len += 1
matched += match_len
pos += match_len
if match_len < seg_len:
break # Partial match, stop
node = child
node.last_access = time.time()
return matched
def insert(self, tokens: tuple) -> 'RadixTreeNode':
"""Insert a token sequence, reusing shared prefixes and splitting nodes as needed."""
node = self.root
pos = 0
while pos < len(tokens):
first_token = tokens[pos]
if first_token not in node.children:
# No matching child → create new leaf node
new_node = RadixTreeNode(tokens[pos:], parent=node)
node.children[first_token] = new_node
self.node_count += 1
return new_node
child = node.children[first_token]
seg = child.tokens
common = 0
for i in range(min(len(seg), len(tokens) - pos)):
if seg[i] != tokens[pos + i]:
break
common += 1
if common < len(seg):
# Partial match → split node (step 4: shared prefix splits)
# Before: parent → child("ABCDE")
# After: parent → mid("AB") → child("CDE")
# → new("CF...")
mid = RadixTreeNode(seg[:common], parent=node)
child.tokens = seg[common:]
child.parent = mid
mid.children[child.tokens[0]] = child
node.children[first_token] = mid
self.node_count += 1
if pos + common < len(tokens):
new_node = RadixTreeNode(tokens[pos + common:], parent=mid)
mid.children[tokens[pos + common]] = new_node
self.node_count += 1
return new_node
return mid
pos += len(seg)
node = child
node.last_access = time.time()
return node
def evict_lru(self):
"""LRU eviction: remove the least-recently-used leaf node (ref_count == 0)."""
while self.node_count > self.max_nodes:
victim = self._find_lru_leaf()
if victim is None or victim is self.root:
break
parent = victim.parent
key = victim.tokens[0]
if key in parent.children:
del parent.children[key]
self.node_count -= 1
if parent is not self.root and len(parent.children) == 1:
self._merge_with_child(parent)
def _find_lru_leaf(self) -> Optional[RadixTreeNode]:
best, best_time = None, float('inf')
def dfs(node):
nonlocal best, best_time
if not node.children and node.ref_count == 0 and node is not self.root:
if node.last_access < best_time:
best, best_time = node, node.last_access
for child in node.children.values():
dfs(child)
dfs(self.root)
return best
def _merge_with_child(self, node: RadixTreeNode):
child = list(node.children.values())[0]
child.tokens = node.tokens + child.tokens
child.parent = node.parent
node.parent.children[node.tokens[0]] = child
self.node_count -= 1
# ═══════════════════════════════════════════════════════
# Simulating the figure's steps (1)-(9) in simplified form
# ═══════════════════════════════════════════════════════
tree = RadixTree(max_nodes=8)
# Integer token ids with descriptive labels for clarity
SYS = (10, 11, 12) # "You are a helpful assistant."
HELLO = (20, 21) # "User: Hello! Assistant: Hi!"
WHAT = (30, 31, 32) # "User: What can you do? Assistant: I can ..."
SOLVE = (40, 41) # "User: Solve this problem ... Assistant: Sure! ..."
STORY = (50, 51) # "User: Write a story ... Assistant: Sure! ..."
# --- Step (2): Insert first conversation [sys + hello] → node a ---
seq_a = SYS + HELLO
tree.insert(seq_a)
cached = tree.match_prefix(seq_a)
print(f"Step 2: insert chat_a, cached prefix = {cached} tokens")
# --- Step (3): Insert second conversation [sys + solve] → node b ---
seq_b = SYS + SOLVE
cached = tree.match_prefix(seq_b)
print(f"Step 3: insert chat_b, reused prefix = {cached} tokens (= system prompt)")
tree.insert(seq_b)
# --- Step (4): Two conversations share sys prefix, branch into hello / what ---
seq_c = SYS + WHAT
cached = tree.match_prefix(seq_c)
print(f"Step 4: insert chat_c, reused prefix = {cached} tokens")
tree.insert(seq_c)
# --- Step (6): fork creates parallel branches sharing the parent prefix ---
Q1 = (60, 61) # "Question 1: ... Answer 1: ..."
Q2 = (62, 63) # "Question 2: ... Answer 2: ..."
Q3 = (64, 65) # "Question 3: ..."
fork_base = SYS + HELLO
for q in [Q1, Q2, Q3]:
seq = fork_base + q
cached = tree.match_prefix(seq)
tree.insert(seq)
print(f"Step 6 (fork): branch {q}, reused prefix = {cached} tokens")
print(f"\nTotal nodes in tree: {tree.node_count}")Sample output showing the core advantage — automatic prefix reuse:
Step 2: insert chat_a, cached prefix = 5 tokens
Step 3: insert chat_b, reused prefix = 3 tokens (= system prompt)
Step 4: insert chat_c, reused prefix = 3 tokens
Step 6 (fork): branch (60, 61), reused prefix = 5 tokens
Step 6 (fork): branch (62, 63), reused prefix = 5 tokens
Step 6 (fork): branch (64, 65), reused prefix = 5 tokensEach fork branch automatically reuses 5 tokens of KV Cache (system prompt + hello), corresponding to step (6) in the figure where node e shares the prefix of node a. In production SGLang, this means the prefill computation for those tokens can be entirely skipped.
Comparison with vLLM's PagedAttention:
| Aspect | PagedAttention | RadixAttention |
|---|---|---|
| Focus | Memory management for a single request | KV Cache reuse across requests |
| Data structure | Block Table (page table) | Radix Tree |
| Sharing granularity | Physical block level | Prefix level |
| Discovery | Requires explicit marking | Automatic longest common prefix matching |
2. Compressed Finite State Machine (Compressed FSM)
In LLM programs, users often need to constrain model output to follow specific formats (e.g., JSON Schema). SGLang supports this through the regex parameter.
The Problem with Traditional Approaches
Existing systems convert the regular expression into a Finite State Machine (FSM), then perform token-by-token constrained decoding:
- Maintain the current FSM state
- Retrieve allowed tokens from successor states by scanning the entire vocabulary
- Set invalid token probabilities to zero (mask)
- Sample one token, transition to the next FSM state
The problem: when a portion of the output is deterministic (e.g., the constant string {"summary": " in JSON), even though each position has only one valid next token, the traditional approach still requires token-by-token decoding — one full forward pass per token. This is clearly wasteful.
SGLang's Compression Optimization
SGLang analyzes the FSM's state transition graph and identifies states with a single valid transition (called singular-transition edges). Consecutive singular-transition edges can be compressed into a single edge, skipping multiple deterministic tokens in one forward pass.
Below is an ASCII illustration of this process (corresponding to Figure 4 in the paper):
(a) Original FSM (for a JSON schema regex):
┌─────────────────────────────────────────────────────┐
│ regex: \{"summary": "[\w\d\s]+\.", "grade": "[ABCD][+-]?"\} │
└─────────────────────────────────────────────────────┘
s0 ─{─→ s1 ─"─→ s2 ─s─→ s3 ─u─→ s4 ─m─→ s5 ─m─→ s6 ─a─→ s7
─r─→ s8 ─y─→ s9 ─"─→ s10 ─:─→ s11 ─ ─→ s12 ─"─→ s13
─[free generate \w\d\s]+─→ s14 ─.─→ s15 ─"─→ s16 ─,─→ s17 ...
States s0→s13 each have exactly one successor (singular transition)
Only s13 has multiple successors (can generate any \w\d\s character)
(b) Compressed FSM:
s0 ──{"summary": "──→ s13 ─[\w\d\s]+─→ s14 ──.", "grade": "──→ ...
(one compressed edge) (free gen) (one compressed edge)
(c) Traditional token-by-token decoding (each arrow = one forward pass):
{ → " → s → u → m → m → a → r → y → " → : → " → [word1] → [word2] → ...
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
12 forward passes just to decode the deterministic prefix!
(d) Compressed decoding (skip deterministic tokens):
{"summary": " → [word1] → [word2] → ... → .", "grade": " → A → " → }
(1 forward) (normal) (normal) (1 forward) (decode)(decode)The key insight: multiple tokens on compressed transition edges can be decoded in a single forward pass, since these tokens are fully deterministic and require no model "deliberation".
Code Demonstration
The following Python code demonstrates the core logic of Compressed FSM — building an FSM from a regex pattern, identifying compressible states, and comparing traditional vs. compressed decoding step counts:
import re
from collections import defaultdict
class FSMState:
"""A single state in the Finite State Machine."""
def __init__(self, state_id: int):
self.id = state_id
self.transitions: dict[str, int] = {} # char → next state id
self.is_accept = False
class ConstrainedDecoder:
"""
Demonstrates traditional FSM vs. Compressed FSM constrained decoding.
For simplicity, we manually construct the FSM rather than compiling from regex.
"""
def __init__(self):
self.states: list[FSMState] = []
self.start_state = 0
def add_state(self, is_accept=False) -> int:
sid = len(self.states)
state = FSMState(sid)
state.is_accept = is_accept
self.states.append(state)
return sid
def add_transition(self, from_state: int, char: str, to_state: int):
self.states[from_state].transitions[char] = to_state
def is_singular(self, state_id: int) -> bool:
"""Check if a state has exactly one valid transition (singular)."""
return len(self.states[state_id].transitions) == 1
def compress(self) -> list[tuple[int, int, str]]:
"""
Analyze the FSM and compress consecutive singular-transition edges.
Returns: [(start_state, end_state, compressed_string), ...]
"""
compressed_edges = []
visited = set()
for s in range(len(self.states)):
if s in visited:
continue
if not self.is_singular(s):
continue
# Trace the chain of singular transitions
chain_start = s
chain_chars = ""
current = s
while self.is_singular(current):
char = list(self.states[current].transitions.keys())[0]
next_state = self.states[current].transitions[char]
chain_chars += char
visited.add(current)
current = next_state
if current == chain_start:
break
if len(chain_chars) > 1: # Only worth compressing if length > 1
compressed_edges.append((chain_start, current, chain_chars))
return compressed_edges
def build_json_fsm() -> ConstrainedDecoder:
"""
Build an FSM for a simplified JSON schema:
{"summary": "[free text].", "grade": "[A-D]"}
Transitions:
s0 -{'- s1 -"- s2 -s- s3 -u- s4 -m- s5 -m- s6 -a- s7
-r- s8 -y- s9 -"- s10 -:- s11 - - s12 -"- s13
s13 -[a-z ]- s13 (free generation loop)
s13 -.- s14 -"- s15 -,- s16 - - s17 -"- s18
-g- s19 -r- s20 -a- s21 -d- s22 -e- s23 -"- s24
-:- s25 - - s26 -"- s27
s27 -[A-D]- s28 -"- s29 -}- s30 (accept)
"""
fsm = ConstrainedDecoder()
# Create all states (s0 - s30)
for i in range(31):
fsm.add_state(is_accept=(i == 30))
# Deterministic prefix: {"summary": " (s0 → s13)
prefix = '{"summary": "'
for i, ch in enumerate(prefix):
fsm.add_transition(i, ch, i + 1)
# s13: Free generation zone (any [a-z ] character)
for ch in "abcdefghijklmnopqrstuvwxyz ":
fsm.add_transition(13, ch, 13)
fsm.add_transition(13, ".", 14) # Period ends free generation
# Deterministic suffix: .", "grade": " (s14 → s27)
suffix = '", "grade": "'
for i, ch in enumerate(suffix):
fsm.add_transition(14 + i, ch, 14 + i + 1)
# s27: Grade selection (A/B/C/D)
for ch in "ABCD":
fsm.add_transition(27, ch, 28)
# Closing: "}
fsm.add_transition(28, '"', 29)
fsm.add_transition(29, '}', 30)
return fsm
def simulate_decoding(fsm: ConstrainedDecoder, target: str):
"""Simulate traditional token-by-token decoding."""
state = fsm.start_state
steps = 0
for ch in target:
if ch in fsm.states[state].transitions:
state = fsm.states[state].transitions[ch]
steps += 1
return steps
def simulate_compressed_decoding(fsm: ConstrainedDecoder, target: str):
"""Simulate compressed FSM decoding: deterministic segments in one step."""
compressed = fsm.compress()
jump_table = {start: (end, chars) for start, end, chars in compressed}
state = fsm.start_state
steps = 0
pos = 0
details = []
while pos < len(target):
if state in jump_table:
end_state, chars = jump_table[state]
if target[pos:pos+len(chars)] == chars:
details.append(f" → skip '{chars}' ({len(chars)} tokens, 1 forward pass)")
pos += len(chars)
state = end_state
steps += 1 # Only 1 step!
continue
ch = target[pos]
if ch in fsm.states[state].transitions:
state = fsm.states[state].transitions[ch]
details.append(f" → decode '{ch}' (1 token, 1 forward pass)")
pos += 1
steps += 1
return steps, details
# ═══════════════════════════════════════════════════════
# Run comparison
# ═══════════════════════════════════════════════════════
fsm = build_json_fsm()
target = '{"summary": "this is a good paper.", "grade": "A"}'
# Compression analysis
compressed = fsm.compress()
print("=== Compressed FSM Analysis ===")
for start, end, chars in compressed:
print(f" s{start} → s{end}: compress '{chars}' ({len(chars)} deterministic tokens)")
# Traditional decoding
trad_steps = simulate_decoding(fsm, target)
print(f"\n=== Traditional Token-by-Token Decoding ===")
print(f" Total steps (forward passes): {trad_steps}")
# Compressed decoding
comp_steps, details = simulate_compressed_decoding(fsm, target)
print(f"\n=== Compressed FSM Decoding ===")
for d in details:
print(d)
print(f" Total steps (forward passes): {comp_steps}")
print(f"\nSpeedup: {trad_steps / comp_steps:.1f}x ({trad_steps} steps → {comp_steps} steps)")Sample output:
=== Compressed FSM Analysis ===
s0 → s13: compress '{"summary": "' (13 deterministic tokens)
s14 → s27: compress '", "grade": "' (13 deterministic tokens)
=== Traditional Token-by-Token Decoding ===
Total steps (forward passes): 48
=== Compressed FSM Decoding ===
→ skip '{"summary": "' (13 tokens, 1 forward pass)
→ decode 't' (1 token, 1 forward pass)
...
→ decode '.' (1 token, 1 forward pass)
→ skip '", "grade": "' (13 tokens, 1 forward pass)
→ decode 'A' (1 token, 1 forward pass)
→ decode '"' (1 token, 1 forward pass)
→ decode '}' (1 token, 1 forward pass)
Total steps (forward passes): 24
Speedup: 2.0x (48 steps → 24 steps)26 deterministic tokens (two JSON structural segments) are compressed to just 2 forward passes, reducing total decoding steps from 48 to 24 — a 2x speedup. In production, the more complex the JSON Schema and the more structural characters it contains, the higher the compression ratio.
3. API Speculative Execution
Inspired by CPU branch prediction, when a program has data dependencies (e.g., the result of select determines subsequent branches):
- Speculate: Without waiting for the
selectresult, optimistically launch all possible branches - Verify & rollback: When the
selectresult arrives, keep the correct branch and discard incorrect ones - Benefit: Transform sequential "request-wait-request" into pipelined execution, hiding network latency
This is especially effective when calling remote APIs (e.g., OpenAI API), where network round-trip latency far exceeds compute cost.
实验结果
吞吐量提升
| 任务类型 | 对比基线 | SGLang 加速比 |
|---|---|---|
| LLM 评审 (多维度) | Guidance | 6.4x |
| 多轮对话 | vLLM | 3.1x |
| Tree-of-Thought | LMQL | 2.2x |
| JSON 约束解码 | Outlines | 3.5x |
| 少样本学习 | 原生 API | 1.8x |
关键发现
- RadixAttention 在多轮对话和共享前缀场景下贡献最大的加速
- 压缩 FSM 在结构化输出(JSON/正则)场景下加速显著
- 推测执行 在使用远程 API 时效果最佳
- 三种优化互相正交,可以叠加使用
Experimental Results
Throughput Improvements
| Task Type | Baseline | SGLang Speedup |
|---|---|---|
| LLM Judge (multi-dim) | Guidance | 6.4x |
| Multi-turn Chat | vLLM | 3.1x |
| Tree-of-Thought | LMQL | 2.2x |
| JSON Constrained Decoding | Outlines | 3.5x |
| Few-shot Learning | Raw API | 1.8x |
Key Findings
- RadixAttention contributes the largest speedup in multi-turn chat and shared-prefix scenarios
- Compressed FSM provides significant acceleration for structured output (JSON/regex) tasks
- Speculative Execution works best when using remote APIs
- The three optimizations are orthogonal and can be stacked together
个人思考
- 编程范式创新:SGLang 将 LLM 交互从"调 API"提升为"写程序",
gen()、select()、fork()等原语极大地提高了表达力,同时让运行时有更多优化空间 - 与 vLLM 的互补关系:vLLM 的 PagedAttention 解决了单请求的内存管理问题,而 SGLang 的 RadixAttention 进一步解决了跨请求的 KV Cache 复用问题。两者是不同层次的优化
- 约束解码的未来:压缩 FSM 为结构化输出提供了高效基础,随着 Agent 应用(工具调用、JSON 输出)的爆发,这一方向的重要性只会增加
- 系统-语言协同设计:SGLang 的核心启示是——好的语言抽象不仅让编程更容易,还能暴露更多优化机会给编译器/运行时
推荐阅读
Personal Thoughts
- Programming paradigm shift: SGLang elevates LLM interaction from "calling APIs" to "writing programs". Primitives like
gen(),select(), andfork()greatly increase expressiveness while giving the runtime more room for optimization - Complementary to vLLM: vLLM's PagedAttention addresses memory management for individual requests, while SGLang's RadixAttention solves cross-request KV Cache reuse — optimizations at different levels
- Future of constrained decoding: Compressed FSM provides an efficient foundation for structured output. As Agent applications (tool calling, JSON output) explode, this direction will only grow in importance
- Co-design of system and language: SGLang's key insight is that good language abstractions not only make programming easier, but also expose more optimization opportunities to the compiler/runtime